initial motivation:
When dealing with sequences to sequences, the original approach was to use architecture that relied on an encoder-decoder scheme with a context hidden state to link between the two, although this approach worked fairly well and solved the limitations of many-to-many , it did have its own limitations .
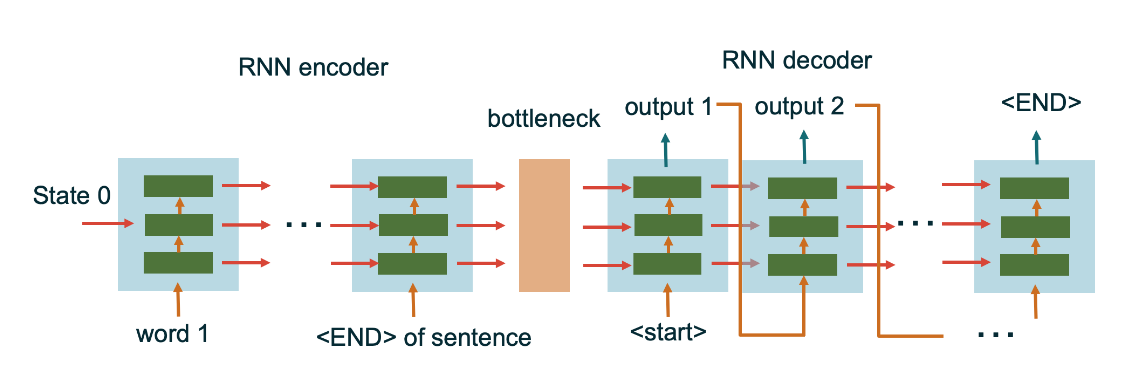
Limitations of the Encoder-Decoder architecture:
- When you look at the previous encoder-decoder architecture, the first thing you might notice is that we’re squeezing all information into one context vector.
- We are losing the nuance of the representation of each timestamp in the encoder.
Our encoder-decoder setup is too rigid. We're forcing a strong inductive bias by assuming all learning happens through a single context state, if only things were that simple.
What do we need?
- Keep the encoder-decoder structure for efficient training.
- Retain a context state to learn the full sequence representation.
- Introduce a way to access different timestamps during decoding.
Ideas:
We will now try to systematically go about potential solutions until we find the best mechanism to answer our previous questions.
Idea 0:
Use a static correspondence from the encoder to the decoder, similar to the architecture.
Problems:
- We usually have a different length of sequences between the encoder and the decoder, this is one of the main benefits of the encoder-decoder architecture, it can naturally deal with the different sequence lengths.
- We can’t know beforehand what block in the encoder corresponds to in the decoder; this is different from images where we have some sense of hierarchy that is symmetric.
- Apart from the architectural considerations, the static routing itself is too limiting, this is not a problem in images due to the strong inductive bias of locality, but there's no similar constraint when talking about sequences, a block in the decoder should naturally have access to more than one state in the decoder.
Question: How to dynamically link between blocks in the encoder and those in the decoder during training time?
Idea 1:
At training time:
- Allow the decoder to send a query .
- Allow all previous blocks, whether inside the encoder or decoder to pick up the query and match it with a generated key .
- Return the value (can be the same as the key) corresponding to the best match.
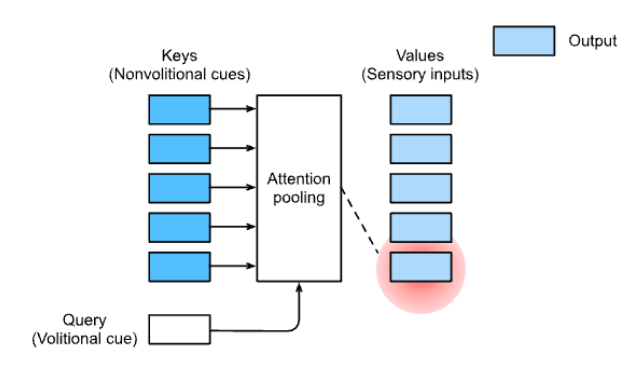
Now let's consider some design considerations with this idea.
Consideration 1:
What should the values for , and be ?
- A first instinct would be to have the key and value as the hidden state at some specific layer in the previous blocks, while the query is the hidden state at this timestamp.
- This is too rigid though, a better approach is to let , , be the output of some , which the input to, is a design choice specific to the application.
- We will then, by training end-to-end find better combinations.
- Think about the training dynamics and how changing these values, puts pressure on the hidden states themselves, we’re pushing the states to learn better representations based on the upstream task.
Consideration 2:
How to match between and ?
Use a hard match between and
- At initialization, the generation of and is random, and nothing would match, gradients are zero and nothing will change ever.
- We would need to use a similarity measure between and .
Consideration 3:
What similarity function to use?
- There are many options here, some good choices are the Inner product or radial basis function .
- Let suppose that
Consideration 4:
The values of (the inner product between and ) can grow very large not due to similarity, but by the mere fact that they’re very high dimensional, this can cause problems in the stability of the Softmax specially early in training.
Let's make the following assumptions, suppose are two random vectors with , where and .
In other words, each component of is drawn from a normal distribution with mean and standard deviation , and the same is true for .
Let's also suppose that and . This is justified if we suppose that and are the result of an initialized with Xavier/Glorot or Kaiming initialization and whose input is normalized.
These are reasonable assumptions, and at initialization we can also suppose that and are somewhat independent.
The goal now is to have similarities , let's calculate the mean and variance of the similarities.
Now since we supposed, :
We can see how the variance grows as the dimension grows, luckily the solution is simple enough, we would only need to normalize by to have variance of !
It's worth mentioning that the similarities can still grow during training, this is why some papers suggest applying layer normalization to the similarities before calculating the attention, you can read more at QKNorm.
Consideration 5:
How to choose from the similarity values while keeping differentiability ?
Suggestion 1: Use .
Look at the computational graph below.
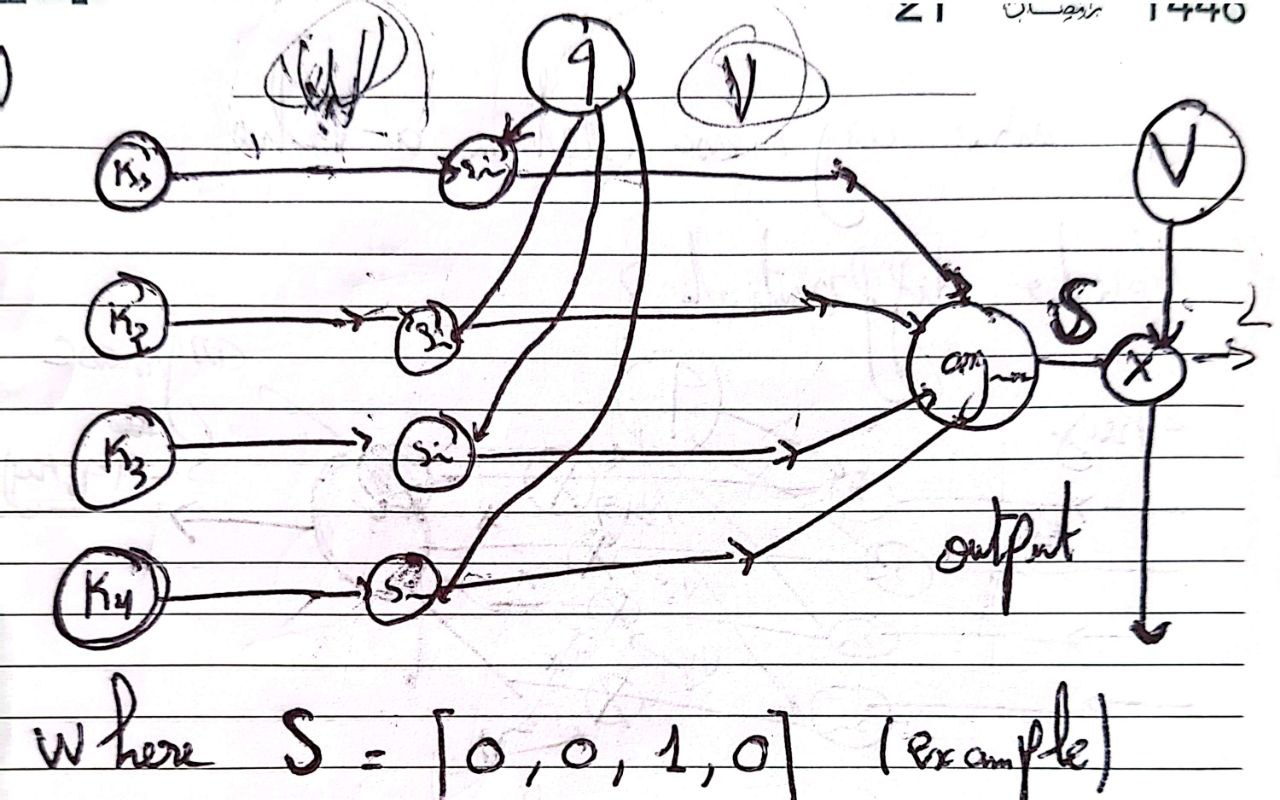
We would have gradients flowing back to the values , but since the is not differentiable (assumed to be ), keys and values will not get any updates, we will never learn a better representation than the one we got at initialization.
A philosophical way to look at this, is that changing the query slightly will not change the match, hence the zero gradients.
Suggestion 2: Use .
We would need to think of a way to select the values after preforming the that is differentiable. There's no clear way to do this.
We might think of using something like:
But the values here aren’t normalized, their influence on deciding the similarities is not something we would want, even if normalized, this doesn’t make much sense.
Also, even if this does work, we get gradients on the keys and queries, but the gradient would only flow to the key with the wining path.
Even though we have gradients, we still wouldn't learn a better combination considering the properties of the function.
From 1 and 2, we can say that whenever we make a hard decision, there’s a gradient problem. We need to soften this hard decision.
Suggestion 3: Use a softened max operation.
A natural choice is the Softmax.
Say we have:
Where are the similarities we defined above.
If is the biggest value, the sum below would be approximately equal to , so the coefficient and for .
Knowing the previous properties, we can use the previous coefficients to calculate a weighted average of values.
So finally we would have:
This is an illustrative figure of the attention mechanism we designed:
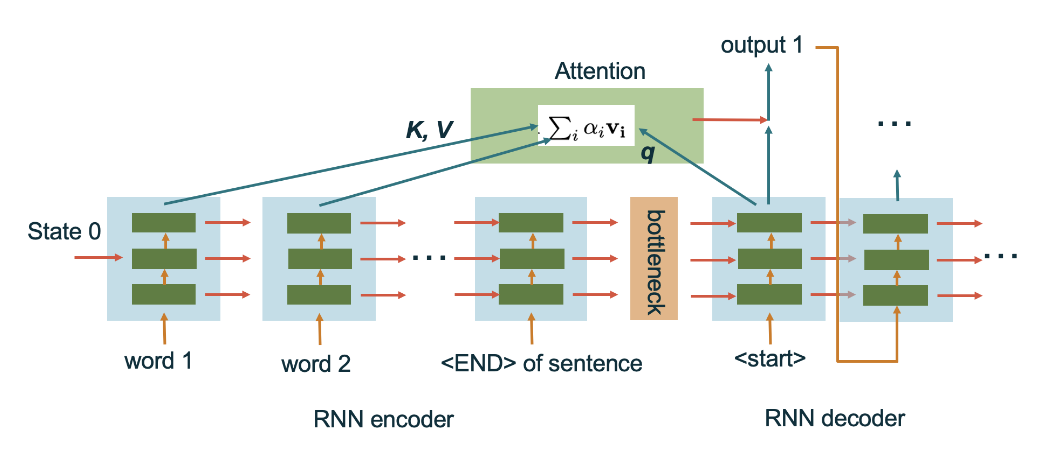
This way of understanding attention gives a strong intuition into the mechanism as we can formulate attention as a mere softened differentiable hash-table/dictionary or a quarriable softened max-pooling.
Now we presented the attention mechanism in the context of but this powerful mechanism, propped the question that changed the field as we know it, is Attention all we need ?
Acknowledgment:
This blog post was heavily inspired by UC Berekely's CS182 course by Anant Sahai.